
mục lục
File pdf là gì?
PDF – Portable Document Format nghĩa là Định dạng Tài liệu Di động là một định dạng tệp do Adobe.com giới thiệu để thể hiện các tài liệu theo cách độc lập với phần cứng/phần mềm/hệ điều hành. Vì vậy, mỗi tài liệu PDF gói gọn thông tin như văn bản, phông chữ, đồ họa, hình ảnh và các thông tin khác cần thiết để hiển thị nó.
Ví dụ: một file pdf có chứa văn bản với font chữ Roboto, nhưng trên máy tính của bạn không có font chữ này. Dù vậy, khi bạn mở file pdf này, bạn vẫn đọc được bình thường mà không có lỗi gì, bởi vì font chữ Roboto đã được nhúng ngay trong file pdf.
Không phải tất cả các file pdf đều có thể tìm kiếm được. Nếu file pdf được tạo bằng phần mềm chỉnh sửa pdf, hoặc thực hiện Save As, “in” pdf thì file đó chứa lớp văn bản trong nội dung của file pdf, nên có thể tìm kiếm được. Nhưng nếu một file pdf được tạo bằng cách scan tài liệu thì sẽ không tìm kiếm được, do là ảnh scan được nhúng vào file pdf mà không có lớp văn bản để tìm kiếm.
Cần phải thực hiện thêm một bước là Nhận dạng ký tự quang học (OCR) để chuyển đổi file pdf này thành tệp PDF có thể tìm kiếm được . Một file pdf có thể tìm kiếm là một tệp PDF được quét với lớp văn bản OCR không nhìn thấy được. Lớp văn bản này được thêm vào bởi một phần mềm chuyển đổi OCR. Lớp văn bản OCR này có thể được tìm kiếm và lập chỉ mục.
Về cơ bản có thể phân loại rộng rãi các tài liệu PDF thành ba loại
- pdf dựa trên văn bản
- pdf dựa trên hình ảnh
- pdf có thể tìm kiếm
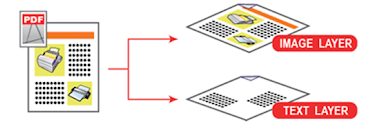
File pdf 1 lớp là gì?
Có 2 loại pdf 1 lớp, gồm pdf 1 lớp hình ảnh và pdf 1 lớp text:
- File pdf 1 lớp hình ảnh là file pdf được tạo thành trong quá trình scan tài liệu bằng máy scan hoặc chụp ảnh tài liệu bằng thiết bị di động.
- File pdf 1 lớp text là file pdf được tạo từ các phần mềm soạn thảo. Ví dụ từ Microsoft Word tiến hành Save As sang pdf sẽ tạo thành file pdf 1 lớp text.
File pdf 1 lớp hình ảnh sẽ không chọn được nội dung, không tìm kiếm được trên nội dung file.
File pdf 2 lớp là gì?
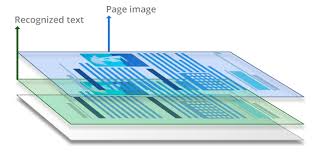
File pdf 2 lớp hay thường gọi là searchable pdf, được tạo từ file pdf 1 lớp hình ảnh, gồm 2 lớp: lớp trên là lớp hình ảnh, lớp dưới là lớp text được đóng trùng khít với lớp hình ảnh phía trên.
Cần phải dùng công nghệ Nhận dạng ký tự quang học (OCR) để chuyển đổi file pdf 1 lớp hình ảnh thành file pdf 2 lớp có thể tìm kiếm được. OCR sẽ tạo thêm một lớp text phía dưới lớp hình ảnh. Những gì chúng ta nhìn ở file pdf đều là lớp hình ảnh, nhưng khi cần tìm kiếm, chỉnh sửa… thao tác được thực hiện ở lớp text.
Mục đích chính của file pdf 2 lớp là để tìm kiếm được trên nội dung file tài liệu. Điều này là rất quan trọng trong nhiều lĩnh vực như lưu trữ tài liệu, bảo hiểm, luật, văn phòng… do khả năng tìm kiếm nhanh chóng mà không cần phải nhớ chính xác từ khóa.
Cách tạo file pdf 2 lớp
Để tạo file pdf 2 lớp có 2 cách chính, nhưng cách nào cũng cần phải có công nghệ OCR:
- Dùng máy scan tạo pdf 2 lớp: hiện nay hầu hết các máy scan hiện đại đều tích hợp công nghệ OCR, cho phép tạo file pdf 2 lớp. Cách này nhược điểm là chậm, tính chính xác đối với tiếng Việt thấp, lớp hình ảnh và lớp text lệch nhau.
- Dùng phần mềm số hóa: Từ file pdf 1 lớp hình ảnh, phần mềm số hóa sẽ dùng công nghệ OCR nhận dạng ký tự, tính toán và thêm 1 lớp text nữa vào bên dưới lớp hình ảnh. Ưu điểm là có khả năng tạo hàng loạt file pdf 2 lớp nhanh chóng, tính chính xác cao. Nhược điểm là phải đầu tư xây dựng phần mềm số hóa, cập nhật liên tục công nghệ OCR để tăng cao độ chính xác. Phần lớn các công ty thực hiện số hóa đều dùng cách này bởi khả năng tạo số lượng lớn file pdf, cho phép triển khai dự án số hóa tài liệu một cách nhanh chóng.
File pdf trong dự án số hóa tài liệu
Hầu hết các dự án số hóa tài liệu hành chính hiện nay đều yêu cầu file pdf sản phẩm phải là file pdf 2 lớp, trừ một số trường hợp tài liệu đặc thù, nhiều chữ viết tay hoặc hình ảnh như sổ hộ tịch, tài liệu đất đai…
Với công nghệ tìm kiếm được xây dựng trong các phần mềm quản lý tài liệu lưu trữ, phần mềm quản lý văn bản… hiện nay như ElasticSearch, Solr… việc yêu cầu file pdf 2 lớp hợp lý. Nó cho phép người dùng tìm kiếm cực nhanh dựa trên nội dung tài liệu, mà không cần nhớ các trường thông tin cơ bản như trích yếu, số văn bản… gần giống với Google Search.









Comments are closed.