mục lục
Đối với dự án số hóa tài liệu thông thường, có nhiều khâu cần thực hiện, trong đó quan trọng nhất là scan tài liệu và nhập dữ liệu đặc tả của hồ sơ, tài liệu. Sản phẩm của quá trình scan tài liệu là file pdf, của quá trình nhập dữ liệu là file dữ liệu chứa các thông tin nằm trong file pdf đó (ví dụ: loại văn bản, ngày tháng năm ban hành, trích yếu nội dung…).
Để có dữ liệu này, có 02 cách: nhập dữ liệu thủ công và trích xuất dữ liệu tự động. Trích xuất tự động nhanh hơn, chính xác hơn nhưng cần đầu tư chi phí. Nhập liệu thủ công chỉ thực hiện với số lượng ít tài liệu, nó không phù hợp để thực hiện trong dự án số hóa tài liệu với hàng triệu file pdf.
Trích xuất dữ liệu là gì?
Trích xuất dữ liệu là sử dụng công nghệ OCR, ICR, OMR để đọc dữ liệu hình ảnh và chuyển sang dạng text, ký tự… để xử lý. Ví dụ:
- Đọc biển số xe để xử lý tốc độ, tính tiền
- Trích xuất loại văn bản, trích yếu nội dung, ngày tháng ban hành… của văn bản hành chính
- Trích xuất tên, năm sinh… từ CMND, CCCD
- Trích xuất loại xe, biển số xe, ngày đăng ký… từ giấy tờ đăng kiểm xe
- …
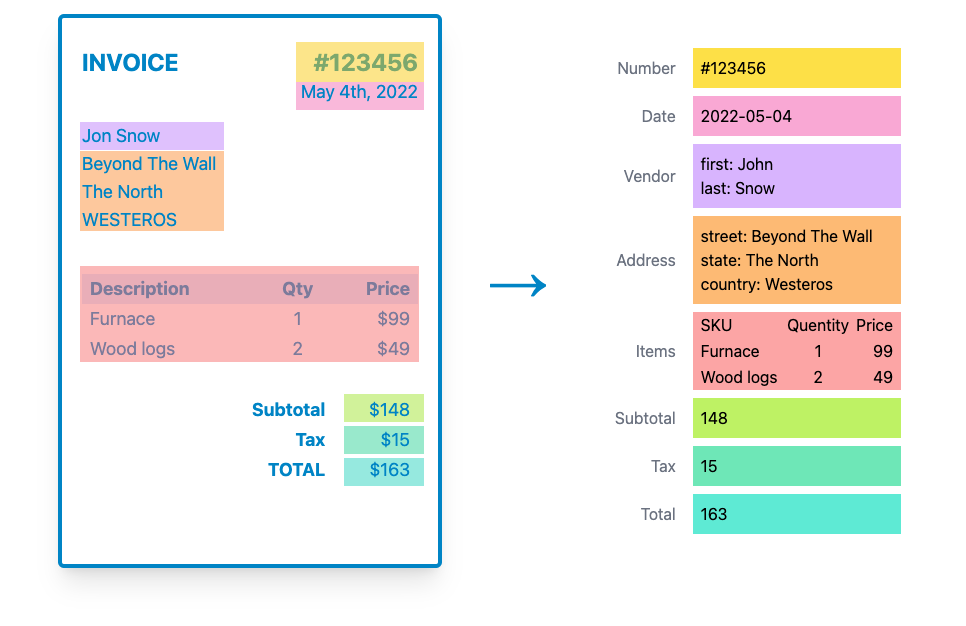
Sau đây là 03 cách trích xuất dữ liệu từ file pdf
Sao chép và dán
Cách đơn giản nhất là sao chép và dán. Nếu chỉ có ít file pdf, sao chép và dán thông tin từ PDF sang chương trình thích hợp (như Excel) có thể là cách đơn giản nhất. Mặc dù đây có thể là cách nhanh nhất để lấy thông tin, nhưng khả năng xảy ra lỗi là rất lớn, sau đó, dữ liệu sẽ cần tổ chức lại theo cách thủ công. Do đó, cách này không phù hợp để thực hiện dự án số hóa tài liệu với hàng triệu file pdf.
Ngoài ra, để có thể sao chép và dán dữ liệu, file pdf này cần phải là file pdf 2 lớp.
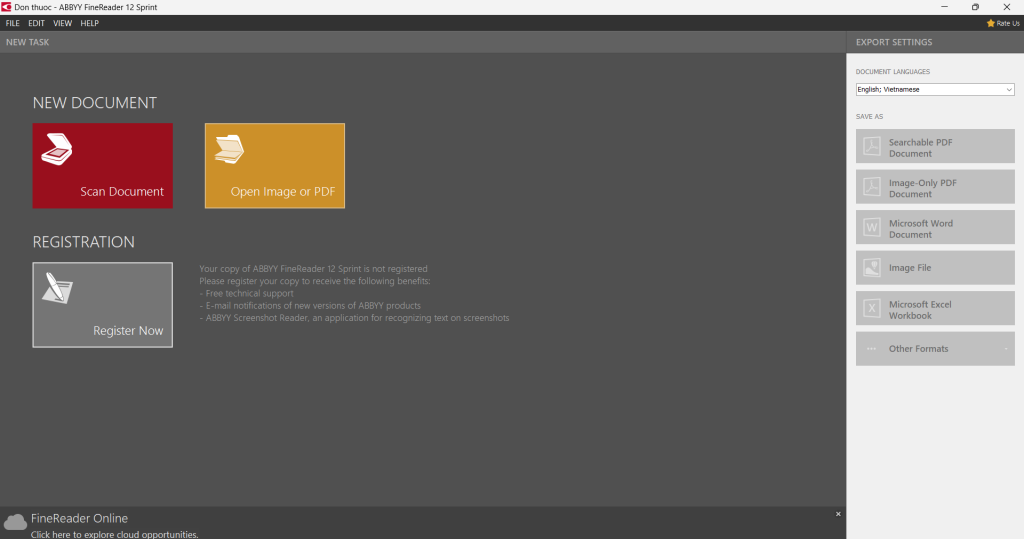
Sử dụng phần mềm chuyển đổi PDF
Có thể sử dụng các phần mềm pdf để chuyển đổi file pdf sang excel, word… rồi copy dữ liệu cần thiết.
Có rất nhiều chương trình để chuyển đổi PDF phổ biến nhất bao gồm Foxit PDF, Candy PDF, Abbyy Fine Reader, FreeOCR, các công cụ online như Google Docs… trong đó Abbyy Fine Reader là tốt nhất để chuyển đổi pdf vì tính chính xác, khả năng giữ nguyên forrm… của nó. Cách này vẫn cần tổ chức lại dữ liệu thủ công do lỗi xảy ra trong quá trình chuyển đổi.
Các lỗi này gần như không thể lường trước, có thể do file pdf bị nghiêng, lệch, có thể do các nhiễu trong file như vết đen, font chữ…
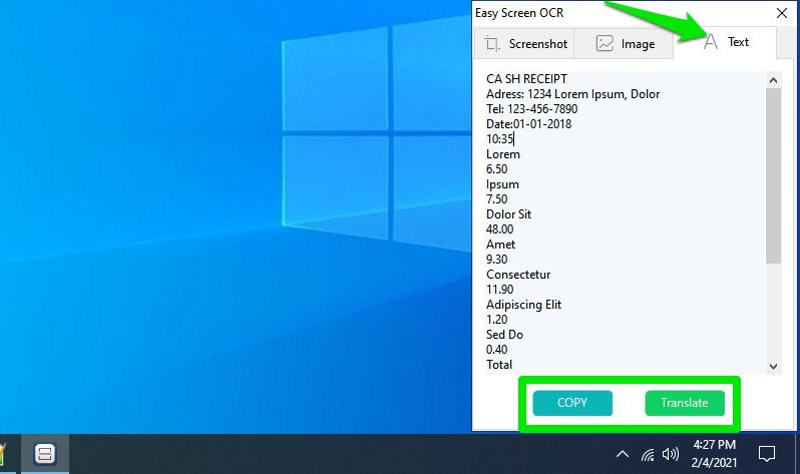
Không thể trích xuất dữ liệu hàng loạt bằng phương pháp này, do vẫn cần chỉnh sửa, tổ chức dữ liệu thủ công, vì vậy nó cũng không phù hợp để triển khai các dự án số hóa.
Tích hợp OCR vào phần mềm
Ở trên đều là các cách dành cho người dùng cá nhân, chỉ xử lý một lượng nhỏ file.
Đối với các công ty triển khai số hóa, cần một giải pháp đồng bộ, tiết kiệm, bảo mật. Giải pháp này phải quản lý được toàn bộ quy trình thực hiện số hóa, trích xuất được dữ liệu từ ảnh để tiết kiệm chi phí, bảo mật tài liệu… Giải pháp này sử dụng kết hợp công nghệ nhận dạng ký tự quang học OCR, nhận dạng biểu mẫu… để tìm và trích xuất dữ liệu từ số lượng lớn file pdf, nó gần như không cần con người can thiệp. Do đó cho phép triển khai số hóa tài liệu hàng loạt với số lượng hàng triệu trang tài liệu
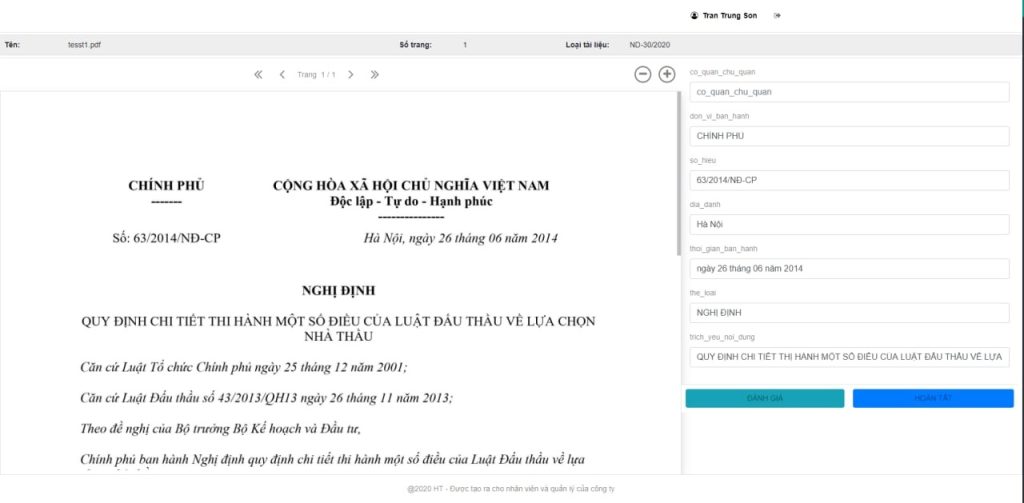
Ngoài ra, giải pháp này còn có quy trình kiểm soát chặt chẽ, nhằm đảm bảo chất lượng của cả quá trình số hóa tài liệu. Một giải pháp như vậy tại Việt Nam thường gọi là phần mềm số hóa tài liệu.
Lưu ý rằng, trích xuất dữ liệu chỉ là một phần của quá trình số hóa tài liệu.









Comments are closed.